\section{Introduction}\label{sec1}
Numerical analysis can be seen as the “operational” part of a scientific computation. In particular, a thorough error analysis is necessary for an informed assessment of the quality of any obtained result. Three examples are considered to illustrate different types of errors and error estimation techniques.
Some preliminaries on machine data representation and error analysis are given in Section 2. In Section 3, two methods of evaluating trigonometric functions are compared with respect to precision. Section 4 illustrates the use of iteration for solving the discrete time matrix algebraic Riccati equation. A third example on numerical integration of a stochastic differential equation is given in Section 5, which shows the application of statistical error analysis. Some conclusions are given in Section 6.
\section{Preliminaries}\label{sec2}
A computer handles pieces of information of a fixed size, a \emph{word}. The number of digits in a word is the \emph{word length}. A normalized \emph{floating point representation} of a real number  is a representation in the form
is a representation in the form
![\[a=\pm m\cdot \beta^{e},\quad \beta^{-1}\leq m<1, \quad e\in\mathbb Z\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-973c54350e4a5198a7476f373afb8364_l3.png "Rendered by QuickLaTeX.com")
All real numbers can be expressed in this representation, where the number  is the \emph{mantissa},
is the \emph{mantissa},  is the \emph{base} and
is the \emph{base} and  is the \emph{exponent}. In a computer, the number of digits for and is limited by the word length.
is the \emph{exponent}. In a computer, the number of digits for and is limited by the word length.
Suppose that  digits are used to represent . Then it is only possible to represent floating point numbers of the form
digits are used to represent . Then it is only possible to represent floating point numbers of the form
![\[\bar{a}=\pm \bar{m}\cdot\beta^{e},\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-a4662a20088acbb599dddada3309bf89_l3.png "Rendered by QuickLaTeX.com")
where  is the mantissa rounded to digits, and the exponent is limited to a finite range
is the mantissa rounded to digits, and the exponent is limited to a finite range
![\[\bar{m}=(.d_1d_2\ldots d_t)_{\beta},\quad 0\leq d_i <\beta, \quad L\leq e\leq U.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-853ae3d6a2f7ea94601b51a6f9bb4e55_l3.png "Rendered by QuickLaTeX.com")
The normalization  ensures that
ensures that  . In the binary system,
. In the binary system,  , so this digit need not be stored. An exception is
, so this digit need not be stored. An exception is  , for which one sets
, for which one sets  , and it is also practical to set
, and it is also practical to set  , the lower limit of the exponent.
, the lower limit of the exponent.
The set of floating point numbers  that can be represented by the system contains exactly
that can be represented by the system contains exactly  numbers. The limited number of digits in the exponent implies that is limited in magnitude to an interval – the \emph{range} of the floating point system. If is larger in magnitude than the largest number in the set , then cannot be represented at all. The same is true, in principle, of numbers smaller than the smallest nonzero number in the set .
numbers. The limited number of digits in the exponent implies that is limited in magnitude to an interval – the \emph{range} of the floating point system. If is larger in magnitude than the largest number in the set , then cannot be represented at all. The same is true, in principle, of numbers smaller than the smallest nonzero number in the set .
It can be shown that in a floating point system, every real number in the floating point range of can be represented with a relative error which does not exceed the \emph{machine unit}  , which, when rounding is used, is defined by
, which, when rounding is used, is defined by
![\[u=\frac{1}{2}\beta^{-t+1}\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-ef99926c61e5f22af39e30425dcf4492_l3.png "Rendered by QuickLaTeX.com")
In a floating point system, both large and small numbers are represented with the same relative accuracy. For most computers, the machine unit lies between  and
and  .
.
The IEEE 754 standard from 1985 for floating point arithmetic is implemented on most chips used for personal computers and workstations. Two main formats, single and double precision, are defined. The standard specifies that arithmetic operations should be performed as if they were first calculated to infinite precision and then rounded off. The default rounding mode is to round to nearest representable number, with round to even in case of a tie. The infinite precision is implemented by using extra guard digits in the intermediate result of the operation before normalization and rounding. In single precision a floating point representation  of a number is stored as
of a number is stored as
![\[v=(-1)^s(1.m)_{2}2^{e-127},\quad 0<e<255,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-893b06ecbfe5cf5b695ca81ae16f49e8_l3.png "Rendered by QuickLaTeX.com")
where  is the sign (one bit), is the exponent (8 bits), and is the mantissa (23 bits). If
is the sign (one bit), is the exponent (8 bits), and is the mantissa (23 bits). If  and
and  are two floating point numbers, the corresponding operations are denoted by
are two floating point numbers, the corresponding operations are denoted by
![\[fl(x+y),\quad fl(x-y),\quad fl(x\cdot y),\quad fl(x/y)\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-1591572251e633e8fdaf9225197003ae_l3.png "Rendered by QuickLaTeX.com")
for the results of floating point addition, subtraction, multiplication and division. These operations have to some degree other properties than the exact arithmetic operations. The associative and distributive laws may fail for addition and multiplication. Consequently, the order of calculation may have a large impact on the error propagation.
An approximation to the machine unit can be determined as  , where
, where  is the smallest floating point number such that
is the smallest floating point number such that
![\[fl(1+x)>1.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-4d1a4837303ed9a26fbe85fcc9fcb349_l3.png "Rendered by QuickLaTeX.com")
The machine unit can therefore be regarded as a lower bound for the relative error in any computation, see [1].
\subsection{Error Types}
Numerical results are influenced by many types of error. Some sources of error are difficult to influence while others can be reduced or eliminated by changing the computational sequence. Errors are propagated from their sources to quantities computed later, sometimes with a considerable amplification. It is therefore important to distinguish between the new error produced at the computation of a quantity, and errors propagated from the data that the quantity is calculated from. The following types of error are encountered in machine computations.
\subsubsection{Errors in Given Input Data}
Input data can be the results of measurements which have been influenced by errors. A \emph{rounding error} occurs, for example, whenever an irrational number is shortened (“rounded off”) to a fixed number of decimals.
\subsubsection{Errors During the Computations}
The limited word length in a computer or calculator leads at times to a loss of information. There are two typical and important cases:
\begin{itemize}\item If the device cannot handle numbers which have more than, say, digits, then the exact product of two -digit numbers (which contains  or
or  digits) cannot be used in subsequent calculations, but is rounded off. \item When a relatively small term
digits) cannot be used in subsequent calculations, but is rounded off. \item When a relatively small term  is added to , then some digits of are “shifted out”, and they will not have any effect on future quantities that depend on the value of
is added to , then some digits of are “shifted out”, and they will not have any effect on future quantities that depend on the value of  . The effect of such roundings can be quite noticeable in an extensive calculation, or in an algorithm which is numerically unstable.\end{itemize}
. The effect of such roundings can be quite noticeable in an extensive calculation, or in an algorithm which is numerically unstable.\end{itemize}
\subsubsection{Truncation Errors}
These are errors arising when a limiting process is truncated (broken off) before the limiting value has been reached. Such \emph{truncation error} occurs, for example, when an infinite series is broken off after a finite number of terms, when a nonlinear function is approximated with a linear function, or when a derivative is approximated with a difference quotient (also called \emph{discretization error}).
\subsubsection{Other Types of Errors}
The most important, but sometimes overlooked sources of error are due to simplifications in the mathematical model, and human or machine errors.
Simplifications in the Mathematical Model
In most of the applications of mathematics, one makes idealizations and assumptions in order to formulate a mathematical model. The idealizations and assumptions made may not be appropriate to describe the present problem and can therefore cause errors in the result. The effects of such sources of error are usually more difficult to estimate than errors in given input data, rounding errors during the computations and truncation errors.
Human Errors and Machine Errors
In all numerical work, one must be aware that clerical errors, errors in hand calculation, and misunderstandings may occur. When using computers, one can encounter errors in the program itself, typing errors in entering the data, operator errors, and (more seldom) machine errors.
Errors in given input data and errors due to simplification of the mathematical model are usually considered to be uncontrollable in the numerical treatment. Truncation errors are usually controllable. The rounding error in the individual arithmetic operation is, in a computer, controllable to a limited extent, mainly through the choice of single and double precision. This type of error can also be reduced by reformulation of the calculation sequence.
\subsection{Functions of a Single Variable}
One of the fundamental extensions of a computing device is to have methods to compute \emph{elementary functions}. A function of a single variable is a mapping  where the argument of
where the argument of  is a one-dimensional variable. For all calculated quantities, the following definition of absolute and relative error can be applied.
is a one-dimensional variable. For all calculated quantities, the following definition of absolute and relative error can be applied.
Theorem: Let  be an approximate value to an exact quantity
be an approximate value to an exact quantity  . The \emph{absolute error} in is
. The \emph{absolute error} in is
![\[\Delta z=\tilde{z}-z,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-c0a563c2d6d4d5499c31dc2e2284ad3e_l3.png "Rendered by QuickLaTeX.com")
and if  , the \emph{relative error} is
, the \emph{relative error} is
![\[\Delta z/z=(\tilde{z}-z)/z.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-a7041530eecf49bb30d68fadaaf89136_l3.png "Rendered by QuickLaTeX.com")
In many situations one wants to compute error bounds, either strict or approximate, for the absolute or relative error. Since it is sometimes rather hard to obtain an error bound that is both strict and sharp, one often prefers to use less strict but often realistic error estimates, see [1].
To carry out rounding error analysis of an algorithm based on floating point operations, a model of how these operations are carried out is needed. The standard model
![\[fl(x \square y)=(x \square y)(1+\delta),\quad |\delta|\leq u,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-5beb51a63ac9f1b00b1fb8a012845cfc_l3.png "Rendered by QuickLaTeX.com")
where  is any of the four elementary operations. The model is valid for the IEEE standard.
is any of the four elementary operations. The model is valid for the IEEE standard.
For a function  , elementary results from calculus can be used to give a bound for the error in the evaluated function value. Let
, elementary results from calculus can be used to give a bound for the error in the evaluated function value. Let  be a function of a single variable and let
be a function of a single variable and let  . Then
. Then
![\[\Delta y=f(x+\Delta x)-f(x)=f'(\xi)\Delta x,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-8b71b983d58c51700aa9557722d82f9e_l3.png "Rendered by QuickLaTeX.com")
where  . Suppose that
. Suppose that  . Then
. Then
![\[|\Delta y|\leq \max_{\xi}|f'(\xi)|\epsilon, \quad \xi\in[x-\epsilon,x+\epsilon].\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-d3181e7a7de41c2954cf7180c34c8f89_l3.png "Rendered by QuickLaTeX.com")
General Error Propagation Formula: Assume that the errors in  are
are  . Then the maximal error in
. Then the maximal error in  has the approximate bound
has the approximate bound
![\[|\Delta f|\lesssim \sum_{i=1}^{n}\left|\frac{\partial f}{\partial x_i}\right||\Delta x_i|.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-ebed1907037fbc38e5738463042c6d67_l3.png "Rendered by QuickLaTeX.com")
\subsection{Vectors and Matrices}
A \emph{vector norm} on  is a function
is a function  satisfying
satisfying
\begin{itemize}\item  \item
\item  \item
\item  \end{itemize}
\end{itemize}
The vector norm of a vector  is denoted
is denoted  . The most common vector norms are special cases of the family of \emph{H\”older norms} or \emph{
. The most common vector norms are special cases of the family of \emph{H\”older norms} or \emph{ -norms}, defined by
-norms}, defined by
![\[\|\mathbf{x}\|_p=(|x_1|^p+|x_2|^p+\cdots+|x_n|^p)^{1/p},\quad 1\leq p<\infty.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-02e48b86f7da35950bbb6b5464ce662e_l3.png "Rendered by QuickLaTeX.com")
The  -norm (or \emph{maximum norm}) is defined
-norm (or \emph{maximum norm}) is defined
![\[\|\mathbf{x}\|_{\infty}=\max_{1\leq i\leq n}|x_i|.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-b8f15e5b22106319f1c07874cb4f0f3e_l3.png "Rendered by QuickLaTeX.com")
An infinite sequence of matrices  is said to converge to
is said to converge to  , that is
, that is  if
if
![\[\lim_{n\rightarrow \infty}\|\mathbf{A}_n - \mathbf{A}\|=0.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-d39dec6a0bf78ba916497321a25baa80_l3.png "Rendered by QuickLaTeX.com")
From the equivalence of norms in a finite dimensional vector space it follows that the order of convergence is independent of the choice of norm. The particular choice  shows that convergence of vectors in is equivalent to convergence of the
shows that convergence of vectors in is equivalent to convergence of the  sequences of scalars formed by the components of the vectors. This conclusion is extended to matrices, see [1].
sequences of scalars formed by the components of the vectors. This conclusion is extended to matrices, see [1].
\subsection{Iteration}
A general idea often used in numerical computation is \emph{iteration}, where a numerical process is applied repeatedly to a problem. As an example, the equation
![\[x=F(x)\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-91c6a462d42362b1da714046d57eb89c_l3.png "Rendered by QuickLaTeX.com")
can be solved by successive approximation using an initial approximation  . By using the equation
. By using the equation  repeatedly, a sequence of numbers
repeatedly, a sequence of numbers  is obtained that (hopefully) converges to a limiting value
is obtained that (hopefully) converges to a limiting value  , which is a root to the equation. As grows, the numbers
, which is a root to the equation. As grows, the numbers  are then successively better and better approximations to the root, that is
are then successively better and better approximations to the root, that is
![\[\lim_{n\rightarrow \infty} x_{n+1}=\alpha =\lim_{n\rightarrow\infty} F(x_n)=F(\alpha),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-cb67c0c083b722c710f7c3407dce933a_l3.png "Rendered by QuickLaTeX.com")
so that  satisfies the equation
satisfies the equation  . The iteration is stopped when sufficient accuracy has been attained. Consider a nonlinear equation of the form
. The iteration is stopped when sufficient accuracy has been attained. Consider a nonlinear equation of the form
![\[x_i=g_i(x_1,x_2,\ldots,x_n), \quad i=1,2,\ldots,n.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-c15048c314d2de11148785321526bbf5_l3.png "Rendered by QuickLaTeX.com")
Then, for  , the \emph{fixed-point iteration}
, the \emph{fixed-point iteration}
![\[x_{i}^{(k+1)}=g_i(x_1^{(k)},x_2^{(k)},\ldots,x_n^{(k)}), \quad i=1,2,\ldots,n\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-c4bf4bb84f082f83312f9d44c7ae6aac_l3.png "Rendered by QuickLaTeX.com")
can be used to find the root to the equation. If  is continuous and
is continuous and  , then
, then  and
and  solves the system
solves the system  .
.
Generally, a vector sequence is said to converge to a limit if
![\[\lim_{k\rightarrow \infty}\|\mathbf{x}^{(k)}-\mathbf{x}^{\ast}\|=0\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-2f197e2e23e3f844bb863df438716578_l3.png "Rendered by QuickLaTeX.com")
for some norm  , see [1].
, see [1].
\subsection{Numerical Stochastic Integration}
Consider an initial value problem consisting of an ordinary differential equation and an initial value,
![\[\dot{x}=\frac{dx}{dt}=a(t,x),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-5d91179bfb7fdd1f73b27728823218fb_l3.png "Rendered by QuickLaTeX.com")
![\[x(t_0)&=&x_0\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-43cf36ad13a852bc2717d06aa822891f_l3.png "Rendered by QuickLaTeX.com")
There is a multitude of methods available for numerical evaluation of the integral. One simple and common method is the \emph{Euler method}, in which the derivative is approximated with a forward time difference equation as
![\[\frac{dx}{dt}=\frac{y_{n+1}-y_n}{\Delta_n},\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-f580ed40c9dde6526cec62b2ad398fdc_l3.png "Rendered by QuickLaTeX.com")
for some given time discretization  , which gives the Euler method for the problem
, which gives the Euler method for the problem
![\[y_{n+1}&=&y_{n}+a(t_n,y_n)\Delta_n,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-f48bd23a8d717cb572628ad8736bc12a_l3.png "Rendered by QuickLaTeX.com")
![\[\Delta_n&=&t_{n+1}-t_n,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-3c83009e20da5cbb6f78299a8c6cb816_l3.png "Rendered by QuickLaTeX.com")
![\[y_0&=&x_0.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-ade62b277f3b0f78ffe82a36862e042b_l3.png "Rendered by QuickLaTeX.com")
For the Euler method, the \emph{local discretization error}, the error introduced in each step of the method, is defined as
![\[l_{n+1}=x(t_{n+1};t_n,y_n)-y_{n+1},\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-46d6d0e5707ff10b58bc10f4d3e57b5c_l3.png "Rendered by QuickLaTeX.com")
and the \emph{global discretization error}, the total error after steps, is defined as
![\[e_{n+1}=x(t_{n+1};t_0,x_0)-y_{n+1}.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-3628f9a666193b05078a3424af5025b6_l3.png "Rendered by QuickLaTeX.com")
A method is \emph{convergent} if the global discretization error converges to zero with the maximum time step  , that is,
, that is,
![\[\lim_{\Delta \downarrow 0}|e_{n+1}|=\lim_{\Delta \downarrow 0}|x(t_{n+1};t_0,x_0)-y_{n+1}|=0,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-f65c28c4abb2b349a63bdc27c9da85ec_l3.png "Rendered by QuickLaTeX.com")
where  on any finite time interval
on any finite time interval ![[t_0,T]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-0e91a29add73416b64d410d6c7301487_l3.png "Rendered by QuickLaTeX.com") . A method is \emph{stable} if the propagated errors remain bounded.
. A method is \emph{stable} if the propagated errors remain bounded.
Now, consider an \emph{It{\^o} process}  satisfying the stochastic differential equation
satisfying the stochastic differential equation
![\[dX_t&=&a(t,X_t)dt+b(t,X_t)dW_t,\quad t_0\leq t\leq T,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-de50b54bcf250b7a221dcca4b733fc2b_l3.png "Rendered by QuickLaTeX.com")
![\[X_{t_0}&=&X_0.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-5ecbc8c7a2524adfff75c9ac31792c01_l3.png "Rendered by QuickLaTeX.com")
For a given discretization  of the time interval , the \emph{Euler-Maruyama approximation} is the continuous stochastic process
of the time interval , the \emph{Euler-Maruyama approximation} is the continuous stochastic process  satisfying
satisfying
![\[Y_{n+1}=Y_{n}+a(\tau_n,Y_n)(\tau_{n+1}-\tau_n)+b(\tau_n,Y_n)(W_{\tau_{n+1}}-W_{\tau_n}),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-5910fc8950c73080c9f11909b59bfd87_l3.png "Rendered by QuickLaTeX.com")
for  with initial value
with initial value  ,
,  and
and  . The process is constructed by generating a white noise process approximation
. The process is constructed by generating a white noise process approximation
![\[\Delta W_n=(W_{\tau_{n+1}}-W_{\tau_n})\sim\mathop{\mathrm{N}}(0,\Delta_n),\quad n=0,1,\ldots,N-1,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-dc81aa784b738d1cf6dd42847a674a44_l3.png "Rendered by QuickLaTeX.com")
of the Wiener process  , that is, the increments of the Wiener process are normally distributed with a variance equal to the time step length. The white noise process therefore has the properties that
, that is, the increments of the Wiener process are normally distributed with a variance equal to the time step length. The white noise process therefore has the properties that
![\[\mathop{\mathbf{E}}(\Delta W_n)=0,\quad \mathop{\mathbf{E}}((\Delta W_n)^2)=\Delta_n.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-c9780930118fb614e78b6c0efdf82772_l3.png "Rendered by QuickLaTeX.com")
In order to generate a continuous function, piecewise constant interpolation is performed to give
![\[Y(t)=Y_{n_t}+\frac{t-\tau_{n_t}}{\tau_{n_t+1}-\tau_{n_t}}(Y_{n_t+1}-Y_{n_t}),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-af699042bce4e0f0fa22fe5a81e9c464_l3.png "Rendered by QuickLaTeX.com")
with  . Error estimates for deterministic problems cannot be used in this case. However, if the exact solution is known, a statistical analysis based on simulation can be used to determine the global discretization error. By using path-wise approximations, the expectation of the global discretization error is
. Error estimates for deterministic problems cannot be used in this case. However, if the exact solution is known, a statistical analysis based on simulation can be used to determine the global discretization error. By using path-wise approximations, the expectation of the global discretization error is
![\[\epsilon=\mathop{\mathbf{E}}(|X_T -Y(T)|).\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-22362855d8ba7b4ccded70532d1c91d7_l3.png "Rendered by QuickLaTeX.com")
The approximation  with maximum step size
with maximum step size  \emph{converges strongly} to
\emph{converges strongly} to  at time
at time  if
if
![\[\lim_{\delta \downarrow 0}\mathop{\mathbf{E}}(|X_T -Y^{\delta}(T)|)=0.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-c4e6819490935b9b42bd72d01269eb9f_l3.png "Rendered by QuickLaTeX.com")
The Euler-Maruyama approximation is the simplest useful approximation for stochastic integration. It is, however, not very numerically efficient. A comprehensive discussion on numerical stochastic integration is given in [2].
\section{Evaluation of Trigonometric Functions}\label{sec3}
The evaluation of trigonometric functions consists of two numerical problems; the approximation of the irrational number  – which cannot be expressed in a finite sequence of decimals in a floating point representation – and the evaluation of the trigonometric function using basic operations. A numerical experiment was carried out to compare two different methods of evaluation of a trigonometric function with an exact argument. The machine unit on the computer was determined to be
– which cannot be expressed in a finite sequence of decimals in a floating point representation – and the evaluation of the trigonometric function using basic operations. A numerical experiment was carried out to compare two different methods of evaluation of a trigonometric function with an exact argument. The machine unit on the computer was determined to be  , using the method described in section ??.
, using the method described in section ??.
Hida et al. [3] suggest an algorithm giving a precision of four times that of double precision IEEE arithmetic. The method for computing  and
and  uses argument reduction, look-up tables and Taylor expansions. In order to compute , the argument is reduced modulo
uses argument reduction, look-up tables and Taylor expansions. In order to compute , the argument is reduced modulo  , so that
, so that  , due to the fact that the sine function is periodic. Noting that sine and cosine functions are symmetric with respect to
, due to the fact that the sine function is periodic. Noting that sine and cosine functions are symmetric with respect to  and
and  , the argument can be reduced modulo . In general,
, the argument can be reduced modulo . In general,  can be expressed as
can be expressed as  or
or  , so that it is only necessary to compute
, so that it is only necessary to compute  and
and  with
with  . Finally, let
. Finally, let  , where the integer is chosen so that
, where the integer is chosen so that  . With , the constant
. With , the constant  .
.
The value of the sine function with an arbitrary argument can be computed by using the relation
![\[\sin(z+m\pi/1024)=\sin (z)\cos(m\pi/1024)+\cos (z)\sin(m\pi/1024),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-5fb93d5b34b4d12dd851b00bb485cf68_l3.png "Rendered by QuickLaTeX.com")
where  is expanded in a Maclaurin series (Taylor expansion around
is expanded in a Maclaurin series (Taylor expansion around  ) and
) and  and
and  are tabulated pre-computed values. These values are computed using the recursive relation
are tabulated pre-computed values. These values are computed using the recursive relation
![\[\sin\left(\frac{\theta}{2}\right)&=&\frac{1}{2}\sqrt{2-2\cos\theta},\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-bd67cc76f42ccd5dc28f8289b36ec37b_l3.png "Rendered by QuickLaTeX.com")
![\[\cos\left(\frac{\theta}{2}\right)&=&\frac{1}{2}\sqrt{2-2\cos\theta},\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-b001eb53debb2e302c36ed298221def6_l3.png "Rendered by QuickLaTeX.com")
starting with  . By using the trigonometric formulas
. By using the trigonometric formulas
![\[\sin(\alpha\pm\beta)=\sin (\alpha) \cos(\beta) \pm \cos (\alpha)\sin(\beta),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-e07fa1e15896a47e955da24067e3ae31_l3.png "Rendered by QuickLaTeX.com")
![\[\cos(\alpha \pm \beta)=\cos (\alpha) \cos (\beta)\mp \sin (\alpha)\cos (\beta).\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-fa02286c207b21b907057f20329cdb55_l3.png "Rendered by QuickLaTeX.com")
all the values for integers can be computed. Using the reduction of the argument, the convergence rate for the Maclaurin series is significantly increased. The Maclaurin expansion for a function is
![\[f(x)=\sum_{n=0}^{\infty}\frac{f^{(n)}(0)}{n!}x^n,\quad |x|<\infty,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-ecf2e0d21423427d7c0f6e137e598c96_l3.png "Rendered by QuickLaTeX.com")
so that
![\[\sin x&=&x-\frac{x^3}{3!}+\frac{x^5}{5!}-\frac{x^7}{7!}+\ldots,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-3a61aa4794b8477b9ad30e958f3f0cd4_l3.png "Rendered by QuickLaTeX.com")
![\[\cos x&=&1-\frac{x^2}{2!}+\frac{x^4}{4!}-\frac{x^6}{6!}+\ldots,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-28d242e124f2f9be74757d7916192ffd_l3.png "Rendered by QuickLaTeX.com")
![\[|x|&<&\infty,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-73a546201939970536ef47f05737d5a8_l3.png "Rendered by QuickLaTeX.com")
The \emph{remainder} after  terms gives an estimate of the absolute error,
terms gives an estimate of the absolute error,
![\[R_n=\int_0^x f^{(n+1)}(n)\frac{(x-u)^n}{n!}du=\frac{f^{(n+1)}(\xi)x^{n+1}}{(n+1)!},\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-51f047347574a411863c049949a17b79_l3.png "Rendered by QuickLaTeX.com")
for some  . Thus, an upper bound for the absolute error of the trigonometric functions is therefore given by
. Thus, an upper bound for the absolute error of the trigonometric functions is therefore given by  and the number of terms can be chosen as to obtain desired accuracy.
and the number of terms can be chosen as to obtain desired accuracy.
Since the tabulated values are determined with the recursive relation above, the function computation are dependent only on the square root operation, apart from the basic operations. The square root is computed using \emph{Netwton’s method} on the function
![\[f(x)=\frac{1}{x^2}-a\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-f7c9f7510a02609b3d733b4bdd6b4288_l3.png "Rendered by QuickLaTeX.com")
which has the root  . This gives the iterative formula
. This gives the iterative formula
![\[x_{i+1}&=&x_{i}+\frac{x_{i}(1-ax_{i}^2)}{2},\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-aef52253cdab2f11536ccbcda4acb181_l3.png "Rendered by QuickLaTeX.com")
![\[x_0&=&\sqrt{a_0}.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-8252a52bba5a1e832271e45156fcbd0c_l3.png "Rendered by QuickLaTeX.com")
Newton’s method is quadratically convergent and any degree of accuracy in the result can be obtained with the given precision. The square root is obtained by multiplying the result with , that is,  .
.
If the elementary operations are assumed to be performed without losing precision (according to the IEEE standard), then the calculations of would benefit from using the above mentioned method due to that the error in the truncated Maclaurin expansion is smaller the closer to zero the argument is.
The computation of  , where the argument is assumed to be exact, was performed on a personal computer, using two methods; the Maclaurin expansion up to 5 terms without argument reduction (method 1, the result denoted
, where the argument is assumed to be exact, was performed on a personal computer, using two methods; the Maclaurin expansion up to 5 terms without argument reduction (method 1, the result denoted  ), and with argument reduction using the above procedure (method 2,
), and with argument reduction using the above procedure (method 2,  ), respectively. The difference in the calculated results between the methods is
), respectively. The difference in the calculated results between the methods is  . The results are summarized in the following table:
. The results are summarized in the following table:

The result by using method 2, , is here assumed to have the error bound given by the machine unit . The example illustrates how the truncation error depends on the argument. By reducing the argument higher precision can be achieved.
If there is an error in the input, the general error propagation formula (see \autoref{sec2}) can be used to estimate the propagated error in the result,
![\[|\Delta f|\lesssim \left|\frac{\partial f}{\partial x}\right||\Delta x|\approx 1\cdot |\Delta x|.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-cf9ee37bc286de2055c734ba71c961ec_l3.png "Rendered by QuickLaTeX.com")
\section{The Algebraic Riccati Equation}\label{sec4}
Many measurements of events evolving in time can be regarded as signals disturbed by noise representing measurement errors. One mathematical model that can be used to describe this is the \emph{dynamic system}, defined by known \emph{state equations} which has an input signal controlling the states of the system and an output signal, which is the observations of the system states.
A discrete time model can be represented by the matrix equation
![\[\mathbf{x}(k+1)&=&\mathbf{A}(k)\mathbf{x}(k)+\mathbf{B}(k)(\mathbf{u}(k)+\mathbf{v}(k)),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-09933c0d9bcb36d9dbde36399683dbc0_l3.png "Rendered by QuickLaTeX.com")
![\[\mathbf{x}(0)&=&\mathbf{x}_0,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-11e77266998ee56bf91b16e401b8eb64_l3.png "Rendered by QuickLaTeX.com")
where  is the discrete time step. In this representation, the vector represents the state of the system, where the number of state variables is equal to the length of .
is the discrete time step. In this representation, the vector represents the state of the system, where the number of state variables is equal to the length of .
The state at a time  is a linear combination of previous states (at times less or equal to ) and a control variable
is a linear combination of previous states (at times less or equal to ) and a control variable  with a superimposed white noise process
with a superimposed white noise process  . The linear combinations are given by the matrices and
. The linear combinations are given by the matrices and  , respectively. The initial state at time
, respectively. The initial state at time  is
is  . Measurements on the system are represented by the matrix equation
. Measurements on the system are represented by the matrix equation
![\[\mathbf{y}(k)=\mathbf{C}(k)\mathbf{x}(k)+\mathbf{D}(k)\mathbf{w}(k),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-c486dcff7e6dfd64c7dcef4a15fe914f_l3.png "Rendered by QuickLaTeX.com")
where the vector  represents the observed values at time , that is the measurements of some linear combination of the state variables of the system, at time , and a noise component,
represents the observed values at time , that is the measurements of some linear combination of the state variables of the system, at time , and a noise component,  . The linear combinations are defined by the matrices
. The linear combinations are defined by the matrices  and
and  , respectively.
, respectively.
If the input signal is assumed to be constant with an imposed white noise, the \emph{Kalman filter} defines a scheme to obtain the optimal estimation of the actual system states, given the noisy observations , see for example [4].
The Kalman estimator is optimal in the sense that it minimizes the least square error, that is
![\[\mathop{\mathbf{E}}([x_{i}(k)-\hat{x}_{i}(k)]^2).\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-87f01eca4e48d4d467eded6c58ccee18_l3.png "Rendered by QuickLaTeX.com")
The Kalman filter is given by
![\[\hat{\mathbf{x}}(k+1)&=&\mathbf{A}(k)\hat{\mathbf{x}}(k)+\mathbf{K}(k)[\mathbf{y}(k)-\mathbf{C}(k)\hat{\mathbf{x}}(k)],\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-b40a629970409eaa101d50c53171d2ed_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\mathbf{x}}(0)&=&0,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-43429b0d2c07451b97bcc5b0e8a71648_l3.png "Rendered by QuickLaTeX.com")
where the Kalman gain  is given by
is given by
![\[\mathbf{K}(k)=\mathbf{A}(k)\mathbf{P}(k)\mathbf{C}(k)^{\mathrm{T}}[\mathbf{C}(k)\mathbf{P}(k)\mathbf{C}(k)^{\mathrm{T}}+\mathbf{D}(k)\mathbf{D}(k)^{\mathrm{T}}]^{-1},\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-679760f0c0d6d81ddcb815d41f53249f_l3.png "Rendered by QuickLaTeX.com")
and  is the stationary solution to the discrete matrix \emph{Riccati equation}
is the stationary solution to the discrete matrix \emph{Riccati equation}
![\[\mathbf{P}(k+1)=\mathbf{A}(k)\mathbf{P}(k)\mathbf{A}(k)^{\mathrm{T}}-\\&-&\mathbf{A}(k)\mathbf{P}(k)\mathbf{C}(k)^{\mathrm{T}} [\mathbf{C}(k)\mathbf{P}(k)\mathbf{C}(k)^{\mathrm{T}}+\mathbf{D}(k)\mathbf{D}(k)^{\mathrm{T}}]^{-1}\mathbf{C}(k)\mathbf{P}(k)\mathbf{A}(k)^{\mathrm{T}}+\mathbf{B}(k)\mathbf{B}(k)^{\mathrm{T}},\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-10a0a578674756eaea8f61b68e8b4214_l3.png "Rendered by QuickLaTeX.com")
![\[\mathbf{P}(0)&=&\mathbf{P}_0,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-7a155feecca94c9eb11154ccc7aecf44_l3.png "Rendered by QuickLaTeX.com")
Normally the \emph{steady-state matrices}  and
and  for
for  are used.
are used.
It can be shown (see [4]), that if the system is \emph{controllable} and \emph{observable}, then the discrete-time algebraic Riccati equation has a unique positive semi-definite solution.
Definition: \emph{Construct the \emph{controllability matrix}
![\[\mathbf{\Gamma}=(\mathbf{B},\mathbf{A}\mathbf{B},\ldots,\mathbf{A}^{n-1}\mathbf{B}).\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-1a5621682d6e7b5fd822eb2a8ae1412a_l3.png "Rendered by QuickLaTeX.com")
Then the matrix pair  is called \emph{controllable} if
is called \emph{controllable} if  .}
.}
Definition: \emph{Construct the \emph{observability matrix}
![\[\mathbf{\Omega}=\left(\begin{array}{c} \mathbf{C}\\\mathbf{C}\mathbf{A}\\ \vdots\\\mathbf{C}\mathbf{A}^{n-1}\end{array}\right).\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-177184106aef12d04c745b98dd273d0b_l3.png "Rendered by QuickLaTeX.com")
Then the matrix pair  is called \emph{observable} if
is called \emph{observable} if  .}
.}
As a numerical example, let the vertical motion of a cruising aircraft be modelled by the one-dimensional motion of a particle, that is
![\[\ddot{z}(t)=u(t)+v(t),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-e2dcfc1da6b4aa5c088908d602abe692_l3.png "Rendered by QuickLaTeX.com")
where  is the position of the particle and
is the position of the particle and  is the applied force. If
is the applied force. If  is constant (it is assumed here that
is constant (it is assumed here that  ), then the remaining force can be assumed to be the influence of turbulence on the aircraft motion, which is modelled by the white noise process
), then the remaining force can be assumed to be the influence of turbulence on the aircraft motion, which is modelled by the white noise process  . The tracking system performs measurements of the height
. The tracking system performs measurements of the height  , which are assumed to be disturbed by measurement errors modelled by white noise
, which are assumed to be disturbed by measurement errors modelled by white noise  . Define the state space variables to be the position and
. Define the state space variables to be the position and  to be the velocity of the aircraft. Then
to be the velocity of the aircraft. Then
![\[\dot{z}&=&\dot{x}_1=x_2,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-2098c12d46aa3433ae947be4770f0dc4_l3.png "Rendered by QuickLaTeX.com")
![\[\ddot{z}=\dot{x}_2=v,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-0bfcf821dfbd69a83fc8a667ec005dda_l3.png "Rendered by QuickLaTeX.com")
so that
![\[\dot{\mathbf{x}}=\mathbf{A}\mathbf{x}=\left(\begin{array}{cc} 0& 1\\0 &0\end{array}\right)\mathbf{x}+\left(\begin{array}{c} 0\\1\end{array}\right)v,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-32bb3bbd506b7cc4c8a8901e0ebe7239_l3.png "Rendered by QuickLaTeX.com")
![\[\mathbf{y}&=&\mathbf{C}\mathbf{x}+dw=(\begin{array}{cc} 1 &0\end{array})\mathbf{x}+w,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-b33d3b14e9593f161c91f392179c06ab_l3.png "Rendered by QuickLaTeX.com")
where the matrices are time-independent and and are scalar white noise processes. Furthermore, it is assumed that the tracking system is operating in discrete time, sampled with time step  . If is small, the applied force can be approximated by a piecewise constant signal. Integration of the state equation gives
. If is small, the applied force can be approximated by a piecewise constant signal. Integration of the state equation gives
![\[\mathbf{x}(kh+h)=e^{\mathbf{A}h}\mathbf{x}(kh)+\int_{kh}^{kh+h}e^{\mathbf{A}(kh+h-s)}\mathbf{A}v(s)ds=\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-bac53ad3848ad79fd832ff5d5154b1e9_l3.png "Rendered by QuickLaTeX.com")
![\[=e^{\mathbf{A}h}\mathbf{x}(kh)+\int_{0}^{h}e^{\mathbf{A}s}ds\mathbf{B}v(k),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-197b84ee60c336ca392a84fa6839ac0e_l3.png "Rendered by QuickLaTeX.com")
by the assumption of the scalar noise process  being constant on
being constant on ![t\in[kh,kh+h],k\in\mathbb{Z}](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-f813d932e6cdbd173786163d6fd0f604_l3.png "Rendered by QuickLaTeX.com") and being independent of . Series expansion gives
and being independent of . Series expansion gives
![\[e^{\mathbf{A}h}=\mathbf{I}+\mathbf{A}h+O(h^2)=\left(\begin{array}{cc}1 & h\\ 0 & 1\end{array}\right)\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-f92a4f10040943c663f2928147c60a84_l3.png "Rendered by QuickLaTeX.com")
and therefore
![\[\int_{0}^{h}e^{\mathbf{A}s}ds\mathbf{B}v(k)=\int_{0}^{h}\left(\begin{array}{cc}1&s\\0&1\end{array}\right)ds\mathbf{B}v(k)=\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-254e61919531d5b168ded2bec09ffde9_l3.png "Rendered by QuickLaTeX.com")
![\[=\left(\begin{array}{cc}h&\frac{h^2}{2}\\0& h\end{array}\right)\left(\begin{array}{c}0\\1\end{array}\right)v(k)=\left(\begin{array}{c}\frac{h^2}{2}\\h\end{array}\right)v(k),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-6ab5e54d6c86523d65e956d3860da105_l3.png "Rendered by QuickLaTeX.com")
which gives the resulting discrete time state equation
![\[\left(\begin{array}{c}x_1(k+1)\\x_2(k+1)\end{array}\right)=\left(\begin{array}{cc}1&h\\0&1\end{array}\right)\left(\begin{array}{c}x_1(k)\\x_2(k)\end{array}\right)+\left(\begin{array}{c}\frac{h^2}{2}\\h\end{array}\right)v(k),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-78ccc9ddb5b2322c98fe7b27eebe526a_l3.png "Rendered by QuickLaTeX.com")
where  and
and  is the position and velocity of the particle at time
is the position and velocity of the particle at time  , respectively. The system is controllable and observable for
, respectively. The system is controllable and observable for  , since
, since
![\[\mathbf{\Gamma}=\left(\begin{array}{cc} \frac{h^2}{2} &\frac{3h^2}{2}\\ h & h\end{array}\right),\quad \mathbf{\Omega}=\left(\begin{array}{cc} 1 & 0\\1 & h\end{array}\right).\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-3242a15ab5779b24fafdac919fbe16b7_l3.png "Rendered by QuickLaTeX.com")
The discrete time algebraic Riccati equation can be interpreted as a system of nonlinear equations. The form of the equation suggests that the solution can be found by iterating the Riccati equation.
As initial value, any positive definite matrix, for example  , can be used. The result from each iteration is tested component wise using the maximum norm (see \autoref{sec2}), so that the component wise maximum error is used as a stop condition for the iteration. The result after a few iterations is
, can be used. The result from each iteration is tested component wise using the maximum norm (see \autoref{sec2}), so that the component wise maximum error is used as a stop condition for the iteration. The result after a few iterations is
![\[\mathbf{P}_{\infty}=\left(\begin{array}{cc} 0.0744 & 0.1453\\0.1453 & 0.3812\end{array}\right),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-a9cf1d174dec4ed7847c337bdc5313b1_l3.png "Rendered by QuickLaTeX.com")
with a component wise error of approximately . The corresponding Kalman gain and filter are, respectively
![\[\mathbf{K}_{\infty}=\left(\begin{array}{c} 1.7419\\1.7207\end{array}\right),\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-1aa6c6f64b16d24bfd8de2e33803e021_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\mathbf{x}}=\left(\begin{array}{cc} -0.7419 & 0.5000\\-1.7207 & 1.000\end{array}\right)\hat{\mathbf{x}}+\left(\begin{array}{c} 1.7419\\1.7207\end{array}\right)\mathbf{y}.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-853ba3fc3a80f2445a087ba740d964ae_l3.png "Rendered by QuickLaTeX.com")
\section{Numerical Solution of a Stochastic Differential Equation}\label{sec5}
A numerical experiment was performed on the It{\^o} process
![\[dX_t=-X_t dt+X_t dW_t\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-0fa3822b31d553ba09a5193b093038cc_l3.png "Rendered by QuickLaTeX.com")
on the interval ![[0,1]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-25b6d943ab489c05a3dbd5ea29087a48_l3.png "Rendered by QuickLaTeX.com") . The equation has the exact solution
. The equation has the exact solution
![\[X_t=X_0\exp\left(\left(a-\frac{1}{2}b^2\right)t+bW_t\right).\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-b73061752ad1ad385b513f37400994a5_l3.png "Rendered by QuickLaTeX.com")
To make an error estimation on a computer, simulations of the same sample paths of the It{\^o} process and their Euler approximation corresponding to the same sample paths of the Wiener process are repeated  times. The error estimate (see \autoref{sec2}) is given by
times. The error estimate (see \autoref{sec2}) is given by
![\[\hat{\epsilon}=\frac{1}{N}\sum_{k=1}^N|X_{T,k}-Y_{T,k}|.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-bb513fbf816dd2e96c9d4d90450938f4_l3.png "Rendered by QuickLaTeX.com")
In order to estimate the variance  of
of  , the simulations are arranged into
, the simulations are arranged into  batches of simulations each. The average errors
batches of simulations each. The average errors
![\[\hat{\epsilon}_j=\frac{1}{N}\sum_{k=1}^N|X_{T,k,j}-Y_{T,k,j}|\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-8b92b2d345ca97d58c66eb8385d04420_l3.png "Rendered by QuickLaTeX.com")
of the batches are independent and approximately Gaussian for large . Student’s -distribution with  degrees of freedom is used to construct a
degrees of freedom is used to construct a  confidence interval
confidence interval  for
for  , where
, where
![\[\hat{\epsilon}=\frac{1}{M}\sum_{j=1}^M\hat{\epsilon}_j=\frac{1}{NM}\sum_{j=1}^M\sum_{k=1}^N|X_{T,k,j}-Y_{T,k,j}|,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-0704bc219e963261dba4450f98b78763_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\sigma}_{\epsilon}^2=\frac{1}{M-1}\sum_{j=1}^M(\hat{\epsilon}_j-\hat{\epsilon})^2,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-4de0e3e2986e514bafa4417f9b883768_l3.png "Rendered by QuickLaTeX.com")
![\[\Delta\hat{\epsilon}=t_{1-\alpha,M-1}\sqrt{\frac{\hat{\sigma}_{\epsilon}^2}{M}}.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-439791d1d1ada4c09540a17c4fbd42fb_l3.png "Rendered by QuickLaTeX.com")
The Euler method has the order of strong convergence 1/2. The solution was simulated with  steps and the Euler-Maruyama method was used with time step
steps and the Euler-Maruyama method was used with time step  . In order to estimate the global discretization error,
. In order to estimate the global discretization error,  different simulations and approximations were performed times, which yielded the error estimates
different simulations and approximations were performed times, which yielded the error estimates
![\[\hat{\epsilon}=0.0806,\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-457bcf2f1d37efdfe3515d45b00b5cfe_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\sigma}_{\epsilon}^2=6.764\cdot 10^{-4}.\]](https://www.mathgallery.com/wp-content/ql-cache/quicklatex.com-76788ebe35f0bb6e1daaef3b6cb6eec0_l3.png "Rendered by QuickLaTeX.com")
An approximate  confidence interval for , that is, the expected deviation of the Euler-Maruyama approximation from the exact solution at time , is therefore given by
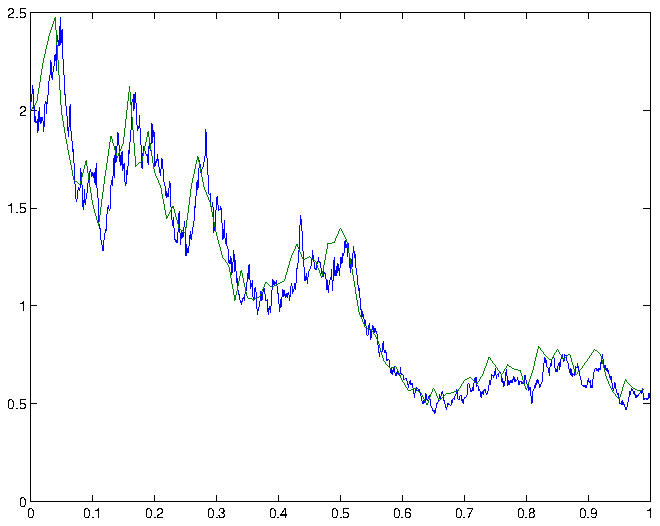
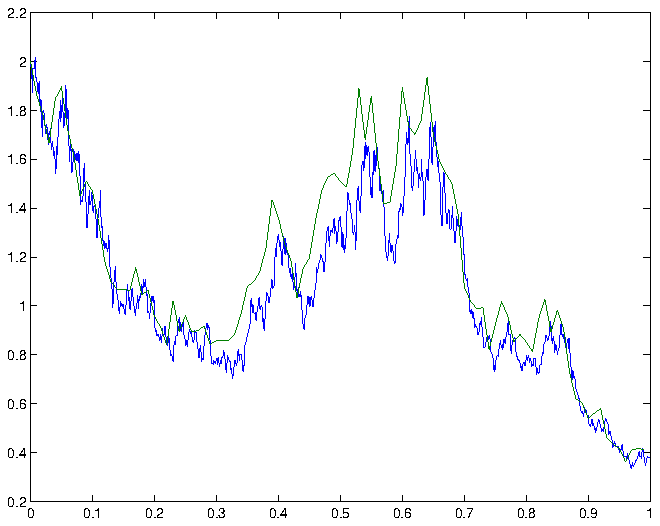
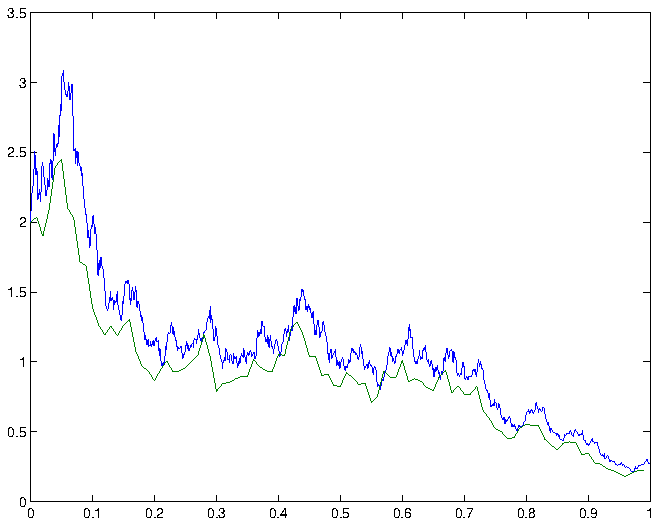
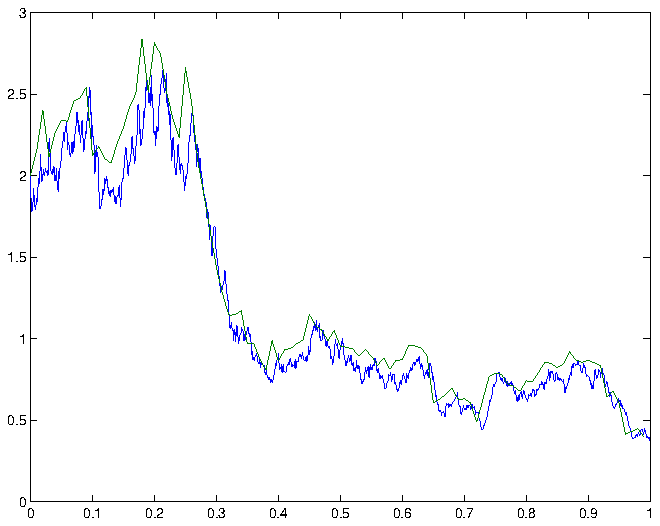
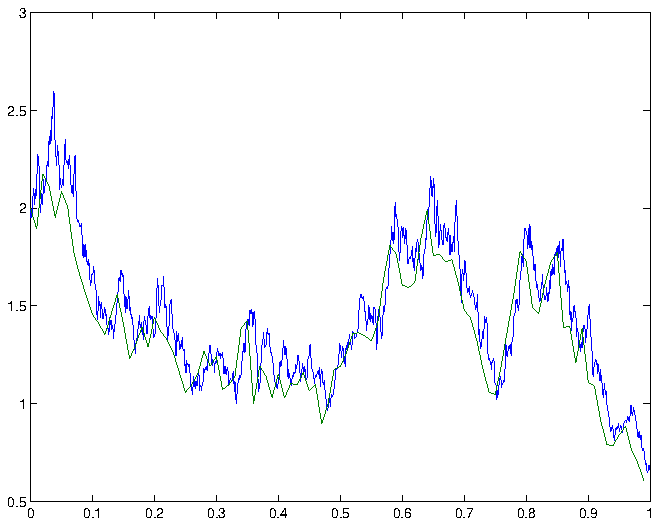
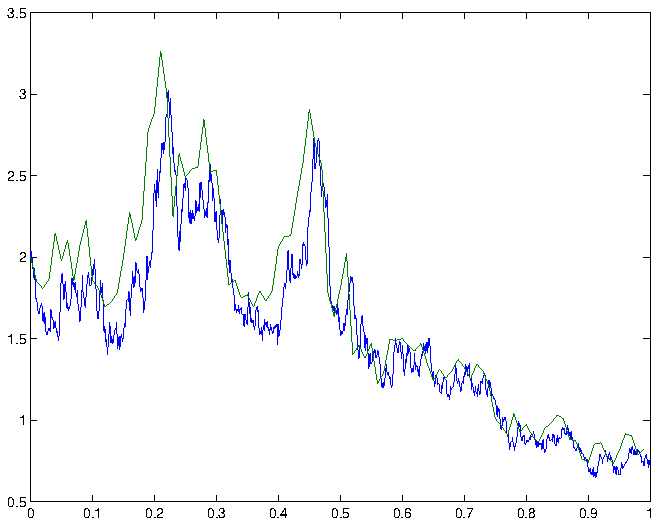
confidence interval for , that is, the expected deviation of the Euler-Maruyama approximation from the exact solution at time , is therefore given by  . Some simulations and the corresponding Euler-Maruyama approximations are shown in figure 1.
. Some simulations and the corresponding Euler-Maruyama approximations are shown in figure 1.
\section{Conclusion}\label{sec6}
In this paper, three examples are given to illustrate estimation of different types of errors. In numerical computation, it is essential to identify error sources and follow the propagation of errors throughout the calculations. Solving a problem using two different methods is a powerful way to distinguish error sources, when this approach is feasible. Two different methods are used to evaluate a trigonometric function, which reveals the impact of different error sources.
For matrix equations, error estimation is more complex, since a suitable (matrix) norm has to be chosen. The discrete time Riccati equation can be solved by iteration, and the use of the maximum norm as a measure of the error is illustrated in the second example.
For numerical solution methods for stochastic problems, statistical methods have to be used for error estimation. This approach is illustrated in the example of numerical solution of a stochastic differential equation.
\section{References}
[bibshow][bibcite key=Approx,SDE,Hida,Control][/bibshow]